Data description
The data used for this project is a subset of All the News 2.0, which contains 2,677,878 news articles American publications spanning from January 1, 2016 to April 2, 2020.
We chose to work with articles from the two publications with the most articles in the dataset: Reuters with 840,094 articles, and The New York Times (NYT) with 252,259 authors.
The dataset contains 10 features: authors, title, article text, url, section, publication and four features describing the time of publication. The features used in this project are: authors, article text, and section.
Preprocessing
While the data is plentiful, a lot of samples are missing entries or has otherwise corrupted entries. To discard these samples, we took the following preprocessing steps
- Remove articles not from Reuters or The New York Times
- Remove articles that are missing either author, section or article
- Remove articles in sections that has fewer than 100 articles
- Remove authors that has written fewer than 5 articles
- Remove articles that has fewer than 2 authors
The preprocessing steps are important to describe since they bias the data and thereby the analysis. In this project we are thus only concerned with articles from the biggest sections of each publication that furthermore is written by at least two authors. These steps discard a signifant part of the dataset especially since most articles are written by a single author thus, the subset of data that we have currated is not an unbiased subset of articles.
The major reason for removing authors with fewer than 5 articles is that the NYT data had celebrities noted as authors for several articles but this preprocessing step discarded most of these articles. See the explainer notebook for all the details.
Statistics
After preprocessing the data, we end up with substantially fewer articles as seen in the summary statistics table below
| Stat | Reuters | NYT |
|---|---|---|
| #Articles | 57,128 | 23,796 |
| #Sections | 39 | 21 |
| #Authors | 1,951 | 1,318 |
| Avg. words pr. article | 622 | 1204 |
| Avg. #articles pr. author | 29 | 18 |
Each article has a section attribute which allow us to get an overview of which topics are most important to the two publications
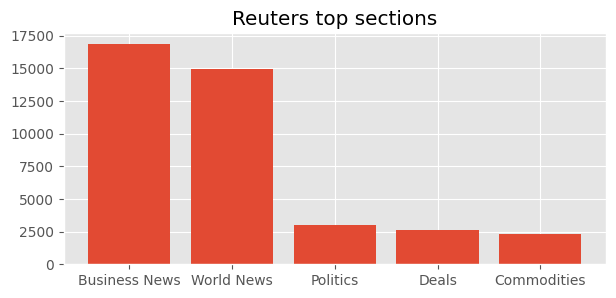
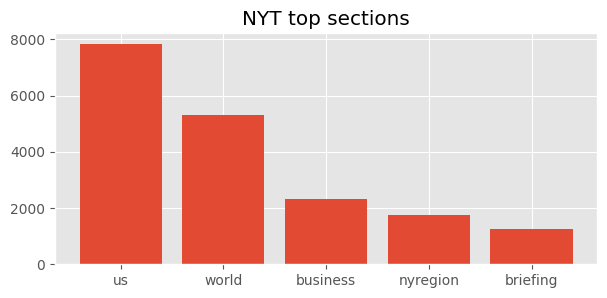
We see that both publications have “world news” and “business news” in their top sections, it’s clear that they emphasize subjects differently. Perhaps not surprisingly, the NYT focuses on US news while Reuters provide a more international perspective with having business first. This fits well with our initial assumptions of Reuters being a more international publication being frequently quoted in even Danish newspapers. With a more international profile, it’s not surprising that Reuters has 18 more sections than the NYT although this could be a result of Reuters having almost twice the number of articles in the dataset than the NYT.
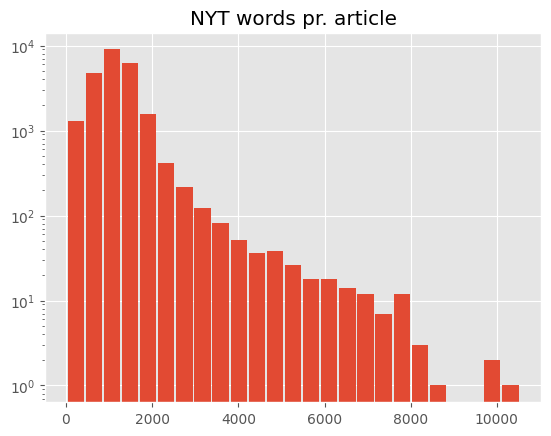
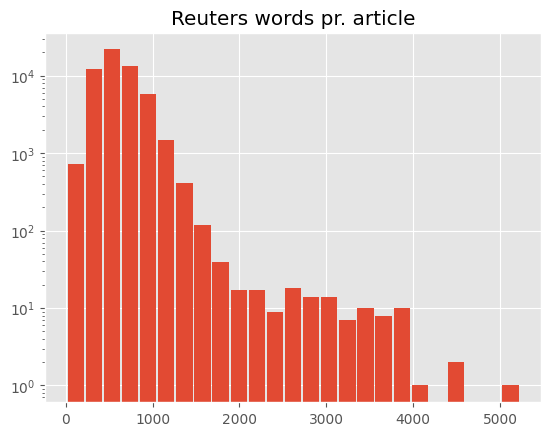
Looking at the distribution of number of word pr. article, it’s apparent that the NYT has a pretty long-tailed distribution (notice the y-axis is log scaled) with some pieces having more then 10,000 words.
The Reuters articles are significantly shorter with the longest ones being just above 5,000 words. We also notice that the bin with the most articles has about 500 words for Reuters but around 1,000 for the NYT. This is also reflected in the statistics table with the NYT having almost twice as many words pr. article as Reuters on average.